出品 | CSDN(ID:CSDNnews)
亚马逊的 AWS 刚“崩”完没多久,微软的 Azure 也崩了......这让很多人好奇,最近的云厂商到底怎么了?
日前,大量用户在 X(原 Twitter)、Hacker News、Reddit 等社交平台上报告称,微软 Azure 出现大规模故障,连 Azure 官网、microsoft.com 都一度无法访问。
根据故障追踪网站 Downdetector 的统计,仅数小时内,全球多个地区的报告就累计上千起报告,显示这次中断影响范围之广,堪称一次全球性事件。

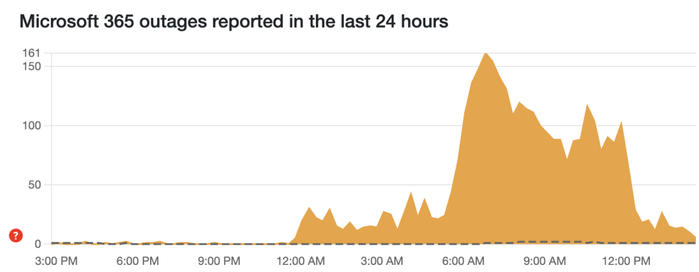

一次全球性宕机,波及各行各业
微软确认,Azure 自 2025 年 10 月 29 日(周三)UTC 时间 16:00(太平洋时间 09:00)起出现大范围中断,预计要到当日 UTC 时间 23:20(太平洋时间 16:20)才能完全恢复。
尴尬的是,这次宕机恰逢微软发布 2026 财年第一季度财报之际(微软的财年并不与日历年同步,其 2026 财年从 2025 年 7 月 1 日开始到 2026 年 6 月 30 日结束)。财报显示,Azure 及其他云服务的收入较去年同期增长了 40%,成为微软在季度财报中披露的增速最快的业务板块。

来源:
https://www.microsoft.com/en-us/Investor/earnings/FY-2026-Q1/press-release-webcast
而此时 Azure 的全球性宕机事件的发生,似乎有些“打脸”。
据微软自己公布的影响范围显示,微软自家的核心业务是“重灾区”,包括 Office 365、Minecraft、Xbox Live 和 Copilot 在内的多项服务均出现不同程度的中断。
微软随后在声明中列出了受影响的 Azure 服务清单,范围之广令人咋舌:
“受影响的服务包括但不限于:App Service、Azure Active Directory B2C、Azure Communication Services、Azure Databricks、Azure Healthcare APIs、Azure Maps、Azure Portal、Azure SQL Database、Container Registry、Media Services、Microsoft Defender External Attack Surface Management、Microsoft Entra ID、Microsoft Purview、Microsoft Sentinel、Video Indexer、Virtual Desktop 等。”
这些项服务几乎涵盖了微软云生态的大半边天。
不仅如此,依赖 Azure 的企业服务也遭殃。
其中,阿拉斯加航空(Alaska Airlines)在其网上上发表声明称,由于微软 Azure 平台发生全球性宕机,托管在其上的阿拉斯加航空和夏威夷航空多项服务中断。航空公司提醒乘客:“无法在线值机的旅客请前往机场柜台领取登机牌,并在候机大厅预留更多时间。”

开源社区同样受波及。当打开 Kubernetes 管理工具 Helm 的官网(get.helm.sh)时,其页面一度返回 “ResourceNotFound” 错误,显示资源无法访问。截至发稿,仍未恢复。

加拿大魁北克的医疗机构 Santé Québec 也报告部分病患访问系统暂停运行——“由于微软 Azure 全球服务中断,一线接入点和虚拟护理平台目前无法使用。”
此外,DownDetector 显示星巴克、克罗格、Costco 等网站都出现了服务中断高峰。

原因揭秘:Azure 的一次意外配置变更
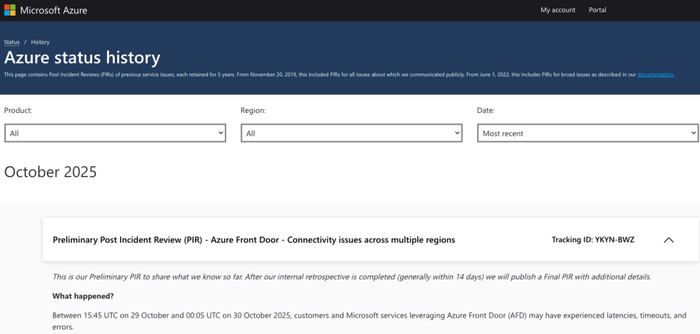
随后,微软发布了初步调查报告,称这次事故的核心在于 Azure Front Door(微软的内容分发网络服务)。
微软表示,在 Azure Front Door(AFD)中,一次意外的租户配置更改引发了广泛的服务中断,影响了依赖 AFD 进行全球内容分发的微软自家服务和客户应用。
这次更改引入了一个无效或不一致的配置状态,导致大量 AFD 节点无法正常加载,从而引发下游服务的延迟增加、超时和连接错误。
随着这些异常节点陆续从全球节点池中掉线,健康节点之间的流量分配出现了严重失衡,放大了故障影响,甚至让部分“健康”区域也出现了间歇性可用的问题。
谈到故障影响范围,外媒 Tom’s Hardware 整理了微软确认的受影响服务和地区,最后甚至调侃道:“微软下次或许可以直接说‘无处不在’就行了!”

而后,微软紧急阻止所有新的配置更改,以防止错误状态继续传播,并开始在全球范围内部署“最后一次已知正常”的配置版本。
恢复过程采取了分阶段、渐进式策略,以确保系统稳定,并防止再次宕机。
最终,问题被追溯到租户配置部署流程中的缺陷:原本用于验证并阻止错误部署的防护机制因软件缺陷失效,导致异常配置绕过安全校验。
微软表示,目前已审查相关防护措施,并紧急增加了新的验证与回滚机制,以防止类似问题在未来重演。
根据微软公布的事故处理时间线显示,整个宕机持续了近 9 个小时:

不过,微软也在初步报告中指出,“目前客户对 AFD 的配置修改仍处于暂时冻结状态。解除后我们将另行通知。虽然整体的错误率与延迟已恢复到事发前水平,但仍有少量客户存在尾部问题,我们正在持续修复中。相关更新将通过 Azure Service Health 直接推送。”

云计算的“集中化风险”被再次放大
事实上,这已经不是本月第一次云平台宕机了。
一周前,亚马逊 AWS 就因 us-east-1 区域 DNS 问题导致全球混乱——热门在线服务瘫痪、航班延误、银行系统受影响。当时 AWS 指出,问题源自 EC2 内部网络监控子系统异常,引发连锁故障。后来即使修复了,网络上关于宕机带来各种损失的争议也一直持续至今。
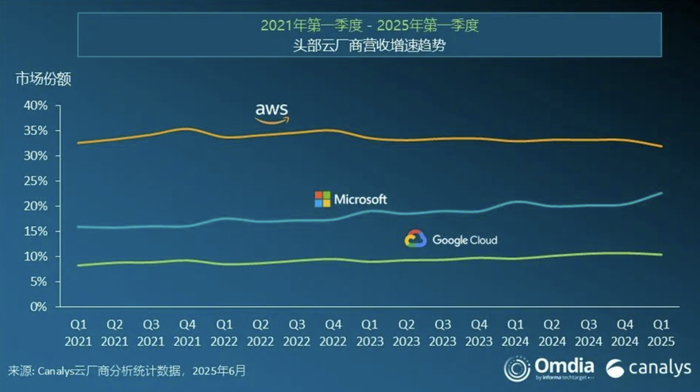
如今,全球云服务市场排名前两的 AWS 和 Azure,连续出问题,这让业内担忧再度升温。
前美国联邦贸易委员会(FTC)委员、消费者金融保护局(CFPB)前主管 Rohit Chopra 在社交媒体上直言:“我们必须意识到,云服务的高度集中不仅带来不便,更是一种真实的系统性脆弱性。”
对于这种情况,美国网站性能监测服务商 Catchpoint CEO Mehdi Daoudi 也发表了自己的看法:“上周 AWS 出故障,这周轮到 Azure,我毫不怀疑下周又会有另一家《财富》100 强企业遭遇类似问题。即便是最先进的基础设施,韧性缺口(系统、基础设施或服务在面对故障、意外或压力时的抵抗力和恢复能力不足的部分)依然普遍存在。Azure 宕机不仅影响核心服务,还波及 DNS 和 CDN 层,使依赖这些服务的工具——比如会话记录和分析平台——完全无法访问。”
他强调,“像这样的宕机在短短几小时内就可能让行业损失数千万美元。这也再次提醒我们,互联网的高度互联意味着一次配置错误或网络边缘变更(例如 AFD 端的问题)都可能迅速波及支撑全球数百万用户的服务。归根结底,韧性必须成为董事会层面的议题,否则这种长时间且代价高昂的宕机事件还会继续发生。”
云计算带来了便利,但也让全球互联网更脆弱。AWS 和 Azure 的接连“罢工”,提醒我们:当少数几家巨头掌控了互联网的大部分神经时,一次配置错误、一次网络异常,就可能引发全球性连锁反应。企业在享受云服务带来的弹性与便捷时,是否也该考虑冗余、多云部署,甚至更多自主控制权?
对此,你有什么样的看法?欢迎留言分享。
参考:
https://azure.status.microsoft/en-gb/status/history/
https://www.tomshardware.com/news/live/aws-outage-strikes-again-colossal-internet-breakdown-strikes-again
https://www.techradar.com/pro/live/microsoft-down-major-outage-hits-azure-365-and-more-even-minecraft-affected